

Sep 10, 2018 •
How we develop new Deep Learning Models for Information Extraction from Documents
At Gini we always strive to improve our information extraction engine. We set off on a journey to enhance our system with developing machine learning (ML) and especially deep learning (DL) algorithms. The techniques we use are based on our own research and state of the art methods.
For the amount and variety of documents we receive, this is a suitable approach and more maintainable than a rule based system.
When it comes to ML, a huge amount of data is crucial for training good models. We are lucky to receive plenty of invoices from our partners that suffice for that task. In domains where we process other types of documents we receive smaller amounts of data. Moreover, all the data we are dealing with is sensitive and we adhere to strict data privacy policies. To meet this challenge we developed a system for data generation and are able to synthesize artificial data (almost) indistinguishable from real documents.
Our main objective has been to develop an ML solution capable of extracting information from structured text that works even better than our current system based on hand crafted rules, regular expressions and CRF models.
We started our research within the Personal Invoice Assistant Academy that focuses on information extraction from invoices and wanted to improve the payment recipient extraction. We framed the problem as classifying words as whether they are part of this extraction or not. After exploring the data, we selected a bunch of features these words have (e.g., their position on the document or whether they appear repeatedly on the document).
The first approaches with a simple feed-forward network did not work better than our already existing system based on CRFs, rules and regular expressions.
This pushed us to further explore more complex architectures and since the information on documents is mostly sequential text, it seemed logical to employ recurrent neural nets (RNNs) which are known to handle sequential information well. Our experiments confirmed this hypothesis. However, RNNs are typically slower to train due to their sequential functioning which can not be parallelized. To overcome this in the future, we will keep on experimenting with other architectures and are following community research closely. Lately, the evidence that other DL methods are able to process sequential data well has been growing. Interesting work on this topic can be found here or in Bai, et al. 2018.
For the time being, building upon lots of experiments we developed an extension to the state of the art NER system presented in Neural Architectures for Named Entity Recognition. In a first step we transform words into vectors by looking them up in an Embedding table. Words we have not seen before and there is no embedding for are mapped to the same vector. To better handle such cases the character sequences are read by a bidirectional LSTM (BiLSTM, a popular instance of RNNs that reads sequences in both directions — forwards and backwards) building up an additional representation of the word. E.g. for German text, the model is able to classify words ending with “straße”, “weg” or “gasse” as street names without having seen the actual word ever before. This step also helps overcoming OCR errors as the final calculation of a word’s representation is tolerant to deviations of a few characters. In addition to pure text we supply positional information of each word to model the 2D structure of documents. After applying another BiLSTM a final CRF layer predicts a word’s class, i.e. if it is part of a certain information we are looking for.
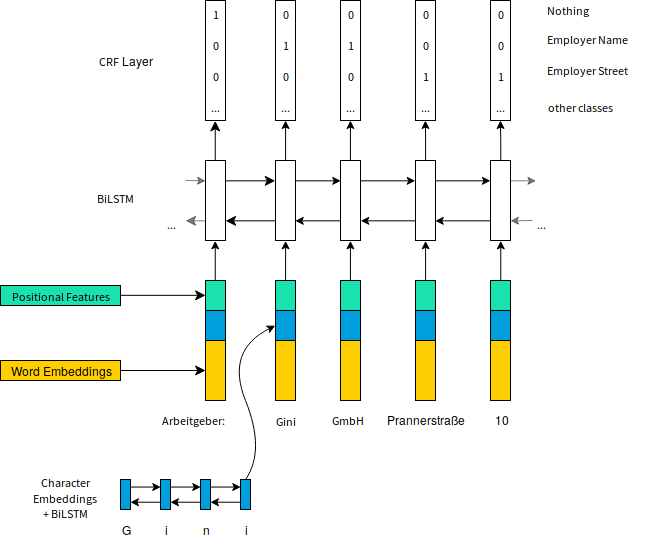
Architecture of the model used for information extraction
. . .
In the Application Handling Academy which deals a lot with payslips we were able to achieve an improvement in extraction accuracy for several fields.
On a set of 100 payslips we achieved the following extraction accuracy rates. Note that some of the information may not be present on all documents and empty extractions are correct for those.
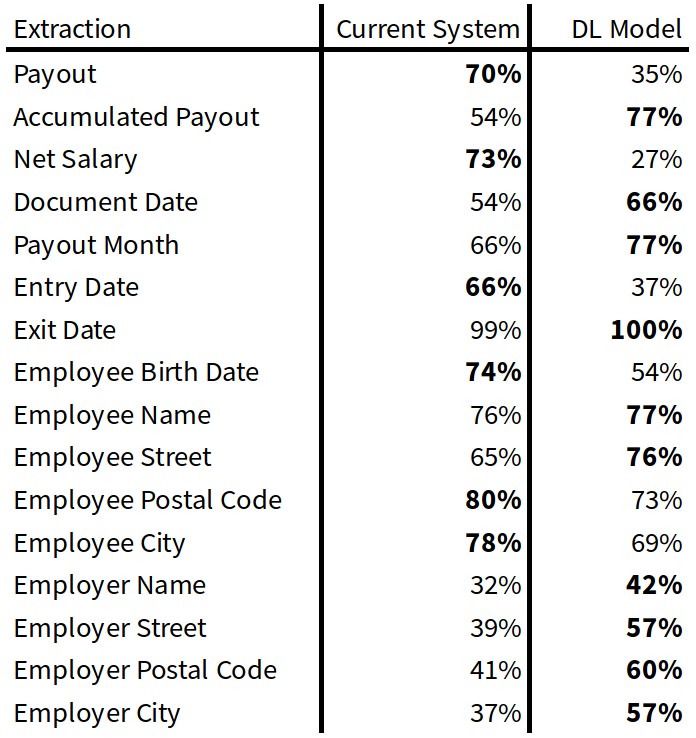
The biggest performance boost can be seen for employer related fields. We attribute this to the models strength in identifying named entities like cities and street names.
We are thrilled by the results we’ve seen so far and are looking forward to further development and bringing more of our DL models into production soon.
Another important finding of our research is that incorporating artificially generated documents for training our models really helps. On average, an increase of the training data set by 30% with artificial data gives an improvement in extraction accuracy by 7.9 percentage points compared to the data set that consists of only real documents. By doubling the size of the training set with generated documents we see an increase by 9.3 percentage points on average. The insight of bigger training set sizes positively influencing performance is not new as such. Good news is that getting the necessary data is a solved problem for us now.
Note that for image data we employ an OCR engine to get machine readable text which increases computational cost. However, the OCR step is not necessary for all use cases and visual information could also help improving extraction quality. That’s why we also research with end to end approaches that directly extract information when given input images and skip the OCR step. More on that topic is to follow in an upcoming post.
. . .
If you read this far, you should probably check out our open positions. We are looking for excellent experts to join us.
At Gini, we want our posts, articles, guides, white papers and press releases to reach everyone. Therefore, we emphasize that both female, male, and other gender identities are explicitly addressed in them. All references to persons refer to all genders, even when the generic masculine is used in content.



