

Jun 22, 2022 •
From image detection to text detection to the recognition of text and post-processing, we created our specialized high-performance OCR to make the best out of mobile images.
The information extraction strongly relies on both text and the coordinates of text in the 2-dimensional document layout.
In native PDF files, text and layout information can be easily parsed from the file. However, the majority of the incoming documents that our Gini system processes are images. More precisely, these are the photos taken with all kinds of smartphones or scanned PDFs created by various scanners. In order to retrieve text and layout data from such files for downstream information extraction tasks, custom Optical Character Recognition (OCR) was implemented.

Figure 1. An example image processing and OCR pipeline in Gini. Left: an example input image. Middle: an ideal preprocessed image. Right: OCR results in JSON format.
Image Processing
The performance of OCR strongly relies on image quality. Therefore, in order to enhance the quality of images, we first implemented a series of convolutional neural network-based models that perform the following data transformations:
- Orientation detection and rotation.
- Homography detection, cropping, and perspective warping.
- Region of interest detection, e.g. tables, QR codes, or remittance slips (“Überweisungsträger” in German, a widely used bank transfer form in Germany and Austria).
- Binarization and de-noising of certain regions of interest (ROIs).
The images obtained after a series of such transformations have corrected orientation, restored perspective, and improved overall quality (Figure 1).
Text Detection
The improved images are now ready for our OCR, and the first step is text detection. It is important to note that modern OCR no longer works on character level but rather utilizes the recent advances in NLP and computer vision deep learning techniques to predict at sequence level (Figure 2). Instead of characters, we extract the snippets of words or even phrases from document images.
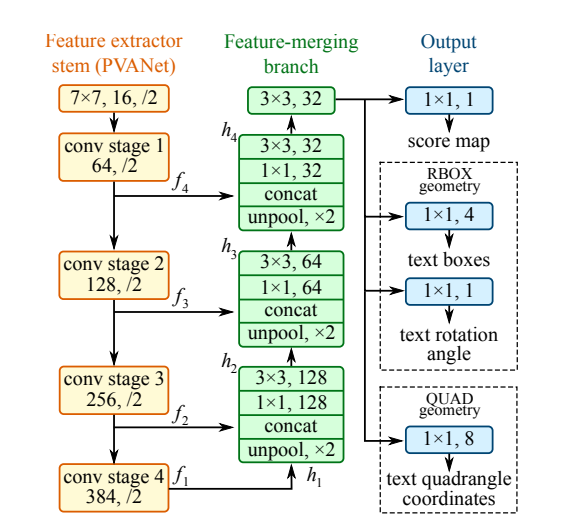
Figure 2. An example of a common text detection model (EAST, Zhou et al., https://arxiv.org/abs/1704.03155).
After the text detection, the full invoice image is split into a batch of snippets, each consisting of 1 or more words closely connected horizontally (Figure 3). It enables the text recognition step to handle them as a sequential word prediction task (a well-studied problem in the NLP domain).

Figure 3. Left: preprocessed image. Right: detected image snippets.
Text Recognition
Once we have batches of image snippets of single-line words or phrases from the text detection step, it is time to transform them into actual text (Figure 5).

Figure 4. The flow of 4-stage scene text recognition (Baek et al., https://arxiv.org/abs/1904.01906).
A typical state-of-the-art text recognition model (Figure 4) consists of the following components:
- Transformation: changing an irregular-shaped text image into a normalized, straight single-line snippet using a certain spatial transformation network.
- Feature extraction: converting the input images into convoluted feature maps using a common convolutional neural network (e.g. VGG, ResNet, RCNN). The feature maps contain important visual features emphasized and irrelevant visual features suppressed.
- Sequence Modeling: capturing contextual information via a recurrent neural network (e.g. BiLSTM).
Prediction: predicting text using sequences of feature vectors from the previous step.
After our image preprocessing, the invoice text should be fairly well-structured, not curved or distorted. This allows us to skip the above transformation step and reduce some computational costs. In other words, we are using only 3 out of 4 text recognition steps.

Figure 5. Left: image snippets after the text detection. Right: text recognition results.
Post Processing
With the text predicted via the model described above, bounding boxes calculated via the coordinates of the image snippets, we are only one step away from the information extraction step.
To help our text extractors achieve higher accuracy, we need to perform some post-processing corrections.
- Post-OCR text correction: since the text recognition process already involves a sequence prediction model, there is no need for a lot of correction – the model learns enough information about the language. We only perform some extra corrections with the help of dictionaries. Additionally, we are planning to look into using the pre-trained language models to improve the prediction quality further.
- Reading order correction: despite the fact that we use coordinates in our downstream extraction tasks, the reading order still influences the extraction accuracy. To mitigate this, we implement some reading order correction methods which help us to reconstruct the intended order as close to the original as possible. In the future, we may also implement a pre-trained order detection model (e.g. https://arxiv.org/abs/2108.11591).
- JSON/XML output creation: finally, we put the results into a structured, deserializable output format for both internal downstream information extraction services and API used by our clients/users. We support both JSON and XML formats.

Figure 6. Left: text recognition results. Middle: text after reading order correction. Right: final OCR output in JSON format.
In the end, the structured layout in XML format is passed to downstream information extraction tasks.
Summary
Using a complete, in-house developed pipeline of deep learning-based image processing, OCR, and information extraction, we provide a fast and accurate solution that is specialized for mobile input. It helps banks and insurance to gather the best possible quality from mobile phone input in a decent amount of time to drive great user experiences and stickiness of the features like Photo Payment or Pay Connect.
. . .
If you enjoy mastering challenges of machine learning like this one, you should probably check out our open positions. We are always looking for excellent developers to join us!
At Gini, we want our posts, articles, guides, white papers and press releases to reach everyone. Therefore, we emphasize that both female, male, and other gender identities are explicitly addressed in them. All references to persons refer to all genders, even when the generic masculine is used in content.



