

Jun 22, 2022 •
Von der Bilderkennung über die Texterkennung bis hin zur Nachbearbeitung haben wir unsere spezielle Hochleistungs-OCR entwickelt, um das Beste aus mobilen Bildern herauszuholen.
Die Informationsextraktion ist neben dem Bild auch stark auf den Text und die Koordinaten des Textes im zweidimensionalen Dokumentenlayout angewiesen. In nativen PDF-Dateien können Text- und Layout-Informationen leicht aus der Datei ausgelesen werden. Der Großteil der eingehenden Dokumente, die unser Gini-System verarbeitet, sind jedoch Bilder. Genauer gesagt handelt es sich dabei um Fotos, die mit Smartphones aller Art aufgenommen wurden, oder um gescannte PDFs, die von verschiedenen Scannern erstellt wurden. Um Text- und Layoutdaten aus solchen Dateien für nachgelagerte Informationsextraktionsaufgaben abzurufen, wurde eine spezielle optische Zeichenerkennung (OCR) implementiert.

Abbildung 1. Ein Beispiel für eine Bildverarbeitungs- und OCR-Pipeline in Gini. Links: ein Beispiel für ein Eingangsbild. Mitte: ein ideal vorverarbeitetes Bild. Rechts: OCR-Ergebnisse im JSON-Format.
Bildverarbeitung
Die Leistung der OCR hängt stark von der eingehenden Bildqualität ab. Um die Qualität der Bilder zu verbessern, haben wir daher zunächst eine Reihe von Modellen auf der Grundlage von Convolutional Neural Networks implementiert, die die folgenden Datentransformationen durchführen:
- Erkennung der Ausrichtung und Drehung.
- Erkennung der Homographie, Zuschneiden und perspektivische Verzerrung.
- Erkennung der Bereiche von Interesse, z. B. Tabellen, QR-Codes oder Überweisungsträger (ein in Deutschland und Österreich weit verbreitetes Banküberweisungsformular).
- Binarisierung und Rauschunterdrückung bestimmter Regionen von Interesse (ROIs).
Die nach einer Reihe solcher Transformationen erhaltenen Bilder haben eine korrigierte Ausrichtung, eine wiederhergestellte Perspektive und eine verbesserte Gesamtqualität (Abbildung 1).
Texterkennung
Die verbesserten Bilder sind nun bereit für unsere OCR, und der erste Schritt ist die Texterkennung. Es ist wichtig zu wissen, dass moderne OCR nicht mehr auf Zeichenebene arbeitet, sondern die jüngsten Fortschritte in den Bereichen NLP und Computer Vision Deep Learning nutzt, um Vorhersagen auf Sequenzebene zu treffen (Abbildung 2). Anstelle von Zeichen extrahieren wir Wortfetzen oder sogar Phrasen aus Dokumentenbildern.
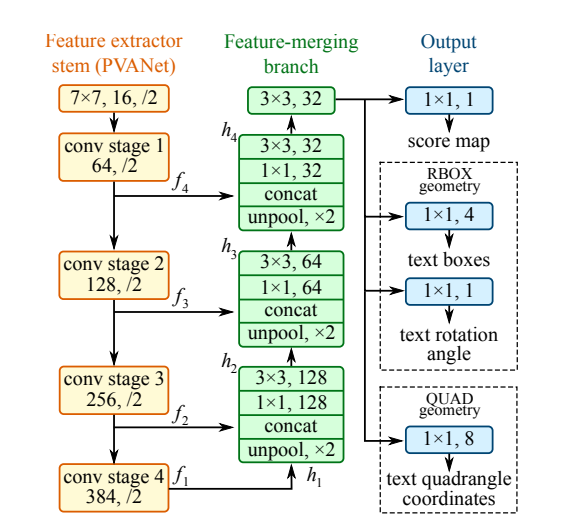
Abbildung 2. Ein Beispiel für ein gängiges Texterkennungsmodell (EAST, Zhou et al., https://arxiv.org/abs/1704.03155).
Nach der Texterkennung wird das vollständige Bild der Rechnung in eine Reihe von Schnipseln aufgeteilt, die jeweils aus einem oder mehreren horizontal eng verbundenen Wörtern bestehen (Abbildung 3). Dadurch kann der Texterkennungsschritt sie als eine sequenzielle Wortvorhersageaufgabe behandeln (eine gut untersuchte Problemstellung im NLP-Bereich).

Abbildung 3. Links: vorverarbeitetes Bild. Rechts: Erkannte Bildschnipsel.
Texterfassung
Sobald wir eine Reihe von Bildausschnitten mit einzeiligen Wörtern oder Sätzen aus dem Texterkennungsschritt vorliegen haben, ist es an der Zeit, sie in echten Text umzuwandeln (Abbildung 5).

Abbildung 4. Der Ablauf der 4-stufigen Erkennung von Szenentext (Baek et al., https://arxiv.org/abs/1904.01906).
Ein typisches modernes Texterkennungsmodell (Abbildung 4) besteht aus den folgenden Komponenten:
- Transformation: Umwandlung eines unregelmäßig geformten Textbildes in ein normalisiertes, gerades, einzeiliges Snippet unter Verwendung eines bestimmten räumlichen Transformationsnetzwerks.
- Merkmalsextraktion: Konvertierung der Eingabebilder in gefaltete Merkmalskarten unter Verwendung eines gängigen Convolutional Neural Network (z. B. VGG, ResNet, RCNN). Die Merkmalskarten enthalten wichtige visuelle Merkmale, die hervorgehoben werden, während irrelevante visuelle Merkmale unterdrückt werden.
- Sequenzmodellierung: Erfassung von Kontextinformationen über ein rekurrentes neuronales Netz (z. B. BiLSTM).
- Vorhersage: Vorhersage von Text anhand von Sequenzen von Merkmalsvektoren aus dem vorherigen Schritt.
Nach unserer Bildvorverarbeitung sollte der Rechnungstext ziemlich gut strukturiert, also weder gekrümmt noch verzerrt sein. Dadurch können wir den obigen Transformationsschritt überspringen und einige Rechenkosten einsparen. Mit anderen Worten, wir verwenden nur 3 von 4 Texterfassungsschritten.

Abbildung 5. Links: Bildschnipsel nach der Texterkennung. Rechts: Ergebnisse der Texterkennung.
Nachbearbeitung
Mit dem durch das oben beschriebene Modell vorhergesagten Text und den über die Koordinaten der Bildausschnitte berechneten Begrenzungsrahmen sind wir nur noch einen Schritt von der Informationsextraktion entfernt.
Um unseren Textextraktoren zu einer höheren Genauigkeit zu verhelfen, müssen wir einige Nachbearbeitungskorrekturen vornehmen.
- Post-OCR-Textkorrektur: da der Texterkennungsprozess bereits ein Sequenzvorhersagemodell umfasst, sind keine großen Korrekturen erforderlich – das Modell lernt genug Informationen über die Sprache. Wir führen lediglich einige zusätzliche Korrekturen mit Hilfe von Wörterbüchern durch. Darüber hinaus planen wir, die Verwendung von vortrainierten Sprachmodellen zu prüfen, um die Vorhersagequalität weiter zu verbessern.
- Korrektur der Lesereihenfolge: obwohl wir bei unseren nachgelagerten Extraktionsaufgaben Koordinaten verwenden, beeinflusst die Lesereihenfolge immer noch die Extraktionsgenauigkeit. Um dies abzumildern, implementieren wir einige Methoden zur Korrektur der Lesereihenfolge, die uns helfen, die beabsichtigte Reihenfolge so nah wie möglich am Original zu rekonstruieren. In Zukunft werden wir möglicherweise auch hier ein vortrainiertes Modell zur Erkennung der Reihenfolge implementieren.
- Erstellung von JSON/XML-Ausgaben: schließlich werden die Ergebnisse in ein strukturiertes, de-serialisierbares Ausgabeformat für interne nachgelagerte Informationsextraktionsdienste und für die von unseren Kunden/Benutzern verwendete API übertragen. Wir unterstützen sowohl JSON- als auch XML-Formate.

Abbildung 6. Links: Ergebnisse der Texterkennung. Mitte: Text nach Korrektur der Lesereihenfolge. Rechts: endgültige OCR-Ausgabe im JSON-Format.
Am Ende wird das strukturierte Layout im XML-Format an nachgelagerte Aufgaben zur Informationsextraktion weitergegeben.
Zusammenfassung
Mit einer kompletten, selbst entwickelten Pipeline aus Deep-Learning-basierter Bildverarbeitung, OCR und Informationsextraktion bieten wir eine schnelle und exakte Lösung, die auf die mobile Fotos spezialisiert ist. Sie hilft unseren Kunden aus Banken und Versicherungen, die bestmögliche OCR Qualität aus Handyfotos in einer angemessenen Zeitspanne zu erfassen, um eine großartige User Experience und eine hohe Akzeptanz von Funktionen wie der Fotoüberweisung oder Pay Connect zu erreichen.
. . .
Wenn Du Spaß daran hast, Herausforderungen des Machine Learnings wie diese zu meistern, solltest Du Dir unsere offenen Stellen ansehen. Wir sind immer auf der Suche nach exzellenten Entwicklern, die sich uns anschließen möchten!
Wir bei Gini möchten mit unseren Beiträgen, Artikeln, Leitfäden, Whitepaper und Pressemitteilungen alle Menschen erreichen. Deshalb betonen wir, dass sowohl weibliche, männliche als auch anderweitige Geschlechteridentitäten dabei ausdrücklich angesprochen werden. Sämtliche Personenbezeichnungen beziehen sich auf alle Geschlechter, auch dann, wenn in Inhalten das generische Maskulinum genutzt wird.



