

May 22, 2018 •
How we quench our AI’s thirst for data
At Gini we build artificial intelligence systems to extract information from documents. One application of our AI technology is the photo payment that analyses invoices to automatically fill fields like IBAN, amount to pay and payment recipient for bank transfers made with mobile banking apps. We are expanding our range of products to other domains which requires us to process additional types of documents and extract additional types of information.
Why bother with generated data?
To launch our system we extended our solid base of semantic rules to work on payslips which hold core information needed for credit applications like the applicant’s salary. With these rules our system reaches average extraction accuracies of about 78%. Here are some of our accuracy rates for specific extractions on 168 sample payslips:
- Document Date: 87%
- Employee’s Birth Date: 90%
- Employee’s Name: 88%
- Employer Name: 37%
- Payout: 85%
- Social Insurance Number: 91%
- Tax Class: 93%
- Child Tax Allowance: 81%
Information about the employer is often written in small letters as can be seen in the example below.
Especially when an image is of low quality, this is hard for our OCR engine to correctly recognize which explains the low accuracy for the employer name above.
Apart from such outliers this is a profound baseline that still does not satisfy our aspiration for excellence (it’s one of our values, see ourv handbookto learn more about them and other aspects of our life at Gini) so we cannot stop there.
This is why we are now developing machine learning models that promise even better results, while not neglecting maintenance of our production system in the meantime 😉.
. . .
One of the biggest challenges when developing machine learning models is gathering the data to train the models with. We do receive a lot of data on a daily basis in our production system, however, this data contains sensitive personal information which we cannot easily use for training. We also irrecoverably delete all production data after 28 days to ensure data security and the constant flux of data adds to these difficulties. And to make matters worse, the data is not always labeled and would require tedious annotation work before being usable for supervised learning approaches.
In order to overcome these shortcomings and still extend our data set, we decided to create artificial documents. We found scraping documents from the web to be not feasible in this domain.
We first determined the requirements our data must fulfill to be used for developing our system. The documents we create must
- conform to data privacy regulations, i.e. not contain any sensible data connected to real people (our products deal with money, so this is a big deal)
- represent real data with respect to layout, content and image quality
- provide ground truth values so we can do supervised learning
Content generation
In a first step we need to create the actual content to create the documents from. For example, among other information, payslips need names and addresses of both employer and employee. To generate these, we compile lists of first and last names as well as street names using publicly available resources such as Wikipedia. By randomly mixing them together and applying some hand-crafted rules to diversify spellings (e.g. different abbreviations) we obtain all the information needed to produce fake addresses.
Numeric values like net salary, payout amount, tax deductions and the accumulated values thereof are computed. We calculate them compliant to tax law, incorporating information about tax class, insurance payments, etc. In total, we generate 95 information fields per payslip.
We can convert this to our ground truth format in a later step by applying according transformations. The requirement of available ground truth values is thus satisfied.
Document generation
To produce documents using the previously generated content, we collect payslips and remove all existing information with graphic editing tools to create empty templates. This step makes it impossible to retrieve any personal data from the final document thus making generated documents conform to our data privacy policies.
For these templates, we define the positions where to put certain information. Filling in the actual information is performed via LaTeX as it has shown the best results over other open source tools.
We emulate the fonts of original documents to make the results look realistic. However, some deviations from real documents are welcome to broaden the diversity of our dataset. We assume these deviations are beneficial for tasks like machine learning as similar variations could also appear in unseen document layouts.
Visual Diversification
The steps so far enable us to generate a variety of documents in PDF format on demand. Real documents we receive from users, however, are often scanned or captured by a mobile phone. We perform several steps to emulate similar visual diversity.
- We first apply various image transformations. These include blurring effects such as motion blur and out-of-focus blur.
- Then we apply affine and perspective transformations to emulate the effects of using a hand-held camera like shaking.
- This is followed by adding a background using random sampling from web-scraped background images (e.g. a cluttered desk).
- Lastly, we add additional illumination variation to our image including brightness and spatial gamma variation to simulate a light source like a camera flash.
Below you can see an example of a generated document with generated data and a transformed variant thereof.

A generated payslip
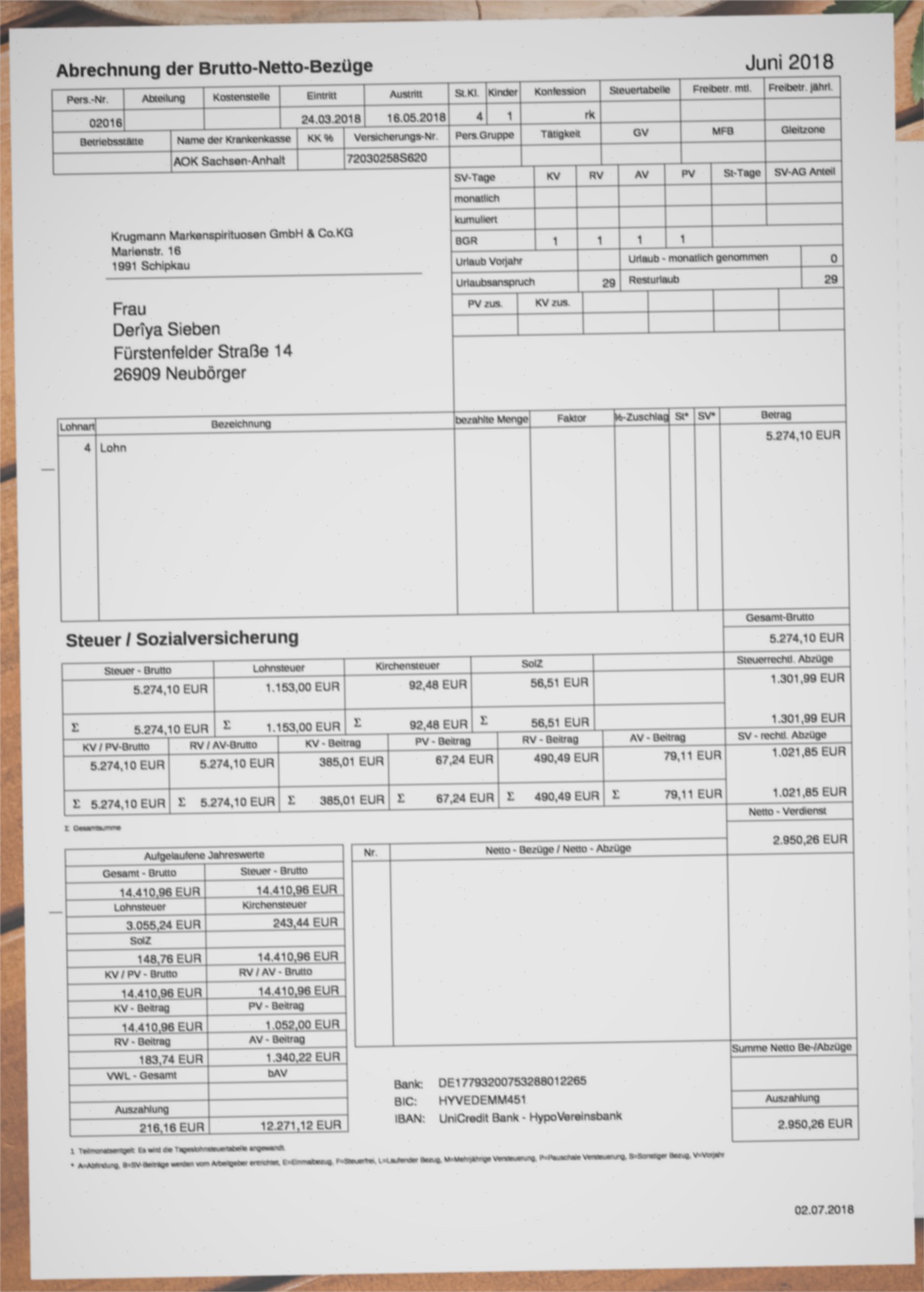
Eine visuell manipulierte Variante der obigen Gehaltsabrechnung
First results
In a preliminary experiment, training a model on a dataset containing about 20% generated payslips reached 2% higher accuracy for one extracted information on a test set of 199 documents in comparison to a model trained the same way on the same data without generated documents. We are looking forward to amplify this improvement further. In upcoming posts we are going to look in more detail on how we develop our machine learning models and how we deploy them to production.
. . .
If you enjoy mastering challenges of machine learning like this one, you should probably check out our open positions. We are looking for excellent tech people to join us.
At Gini, we want our posts, articles, guides, white papers and press releases to reach everyone. Therefore, we emphasize that both female, male, and other gender identities are explicitly addressed in them. All references to persons refer to all genders, even when the generic masculine is used in content.



