

Mai 22, 2018 •
Wie wir den Durst unserer KI nach Daten stillen
Gini nutzt KI-Systeme, um Informationen aus Dokumenten zu extrahieren. Eine Anwendung unserer KI-Technologie ist die Fotoüberweisung, die Rechnungen analysiert, um Felder wie IBAN, Zahlungsbetrag und Zahlungsempfänger für Überweisungen mit z.B. mobilen Banking-Apps automatisch zu füllen. Wir erweitern unsere Produktpalette auf andere Bereiche, was es erforderlich macht, zusätzliche Arten von Dokumenten zu verarbeiten und zusätzliche Arten von Informationen extrahieren.
Warum generierte Daten?
Zum Start unseres Systems haben wir unsere solide Basis an semantischen Regeln erweitert, um mit Gehaltsabrechnungen zu arbeiten, die Kerninformationen enthalten, die für Kreditanträge benötigt werden, wie das Gehalt des Antragstellers. Mit diesen Regeln erreicht unser System eine durchschnittliche Extraktionsgenauigkeit von etwa 78 %. Hier sind einige unserer Genauigkeitsraten für spezifische Extraktionen auf 168 Beispiel-Lohnzetteln:
- Dokumentendatum: 87%
- Geburtsdatum des Mitarbeiters: 90%
- Name des Mitarbeiters: 88%
- Name des Arbeitgebers: 37%
- Auszahlungsbetrag: 85%
- Sozialversicherungsnummer: 91%
- Steuerklasse: 93%
- Kinderfreibetrag: 81%
Informationen über den Arbeitgeber werden oft in kleinen Buchstaben geschrieben, wie man im folgenden Beispiel sehen kann.
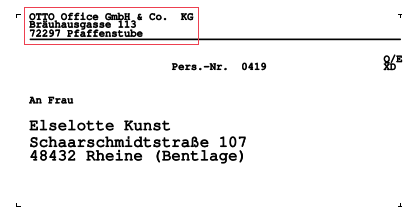
Ein Ausschnitt aus einem generierten Dokument mit zufälligen Daten, die nicht mit einer realen Person in Verbindung gebracht werden
Besonders wenn ein Bild von geringer Qualität ist, ist es für unsere OCR-Engine schwer, dieses korrekt zu erkennen, was die niedrige Genauigkeit für den Arbeitgebernamen oben erklärt.
Abgesehen von solchen Ausreißern ist dies eine fundierte Basis, die allerdings unserem Streben nach Exzellenz (einer unserer Werte, siehe unser Handbuch, um mehr darüber zu erfahren) noch nicht ausreichend gerecht wird, und wir damit noch nicht zufrieden sind.
Darum entwickeln wir maschinelle Lernmodelle, die noch bessere Ergebnisse versprechen, ohne in der Zwischenzeit die Wartung unseres Produktionssystems zu vernachlässigen 😉.
. . .
Eine der größten Herausforderungen bei der Entwicklung von maschinellen Lernmodellen ist das Sammeln der Daten, mit denen die Modelle trainiert werden. Wir erhalten in unserem Produktionssystem zwar täglich viele Daten, allerdings enthalten diese Daten sensible personenbezogene Informationen, die wir nicht ohne weiteres für das Training verwenden können. Außerdem löschen wir alle Produktionsdaten nach 28 Tagen unwiederbringlich, um die Sicherheit der Daten zu gewährleisten. Diese Fluktuation stellt eine weitere Herausforderung dar. Zudem sind diese Daten nicht immer mit den tatsächlichen Werten (die sogenannte Ground Truth) versehen, was mühsam von Hand ergänzt werden muss, bevor sie für überwachte Lernansätze verwendet werden können.
Um diese Herausforderungen zu meistern und dennoch unseren Datensatz zu erweitern, haben wir uns entschieden künstliche Dokumente zu erzeugen. Das Scraping von Dokumenten aus dem Web erwies sich in diesem Bereich nicht praktikabel.
Zunächst legten wir die Anforderungen fest, die unsere Daten erfüllen müssen, damit wir sie für die Entwicklung unseres Systems verwenden können. Die von uns erzeugten Dokumente müssen
- datenschutzkonform sein, d. h. keine sensiblen Daten enthalten, die mit realen Personen in Verbindung stehen (unsere Produkte befassen sich mit den Finanzen von Usern, daher geben wir hier besonders acht)
- echte Daten in Bezug auf Layout, Inhalt und Bildqualität repräsentieren
- Ground-Truth-Werte liefern, damit wir überwachtes Lernen durchführen können
Generierung von Inhalten
Im ersten Schritt müssen wir die eigentlichen Inhalte erstellen, die auf den Dokumenten stehen sollen. Zum Beispiel benötigen Gehaltsabrechnungen neben anderen Informationen die Namen und Adressen von Arbeitgeber und Arbeitnehmer. Um diese zu generieren, stellen wir Listen mit Vor- und Nachnamen sowie Straßennamen aus öffentlich zugänglichen Quellen wie Wikipedia zusammen. Durch das zufällige Mischen dieser Namen und die Anwendung einiger von Hand erstellter Regeln zur Diversifizierung der Schreibweisen (z. B. verschiedene Abkürzungen) erhalten wir alle Informationen, die zur Erzeugung erfundener Adressen benötigt werden.
Es werden numerische Werte wie Nettogehalt, Auszahlungsbetrag, Steuerabzüge und deren kumulierte Werte errechnet. Wir berechnen diese steuerrechtskonform unter Einbeziehung von Informationen über Steuerklasse, Versicherungszahlungen etc. – insgesamt generieren wir 95 Informationsfelder pro Gehaltsabrechnung.
Diese können wir in einem späteren Schritt durch entsprechende Transformationen in unser Ground-Truth-Format umwandeln. Damit ist die Forderung nach verfügbaren Ground-Truth-Werten erfüllt.
Dokumentenerstellung
Um Dokumente mit den zuvor generierten Inhalten zu erstellen, sammeln wir Gehaltsabrechnungen und entfernen alle vorhandenen Informationen mit grafischen Bearbeitungswerkzeugen, um leere Vorlagen zu erstellen. Dieser Schritt macht es unmöglich, personenbezogene Daten aus dem endgültigen Dokument abzurufen, so dass die generierten Dokumente mit unseren Datenschutzrichtlinien konform sind.
Für diese Vorlagen definieren wir die Positionen, an denen bestimmte Informationen platziert werden sollen. Das Ausfüllen der eigentlichen Informationen erfolgt über LaTeX, da es im Vergleich zu anderen Open-Source-Tools die besten Ergebnisse gezeigt hat.
Wir simulieren die Schriftarten der Originaldokumente, um die Ergebnisse realistisch aussehen zu lassen. Einige Abweichungen von echten Dokumenten sind jedoch von Vorteil, um die Vielfalt unseres Datensatzes zu erweitern. Wir gehen davon aus, dass diese Abweichungen für Aufgaben wie maschinelles Lernen sogar wünschenswert sind, da ähnliche Variationen auch in ungesehenen Dokumentenlayouts auftreten könnten.
Visuelle Diversifizierung
Die bisherigen Schritte ermöglichen es uns, bei Bedarf eine Vielzahl von Dokumenten im PDF-Format zu erzeugen. Echte Dokumente, die wir von Benutzern erhalten, sind jedoch oft gescannt oder mit einem Handy aufgenommen. Wir führen mehrere Schritte durch, um eine ähnliche visuelle Vielfalt zu simulieren.
- Zunächst wenden wir verschiedene Bildtransformationen an. Dazu gehören Unschärfeeffekte wie Bewegungsunschärfe und Verwischen.
- Dann wenden wir affine und perspektivische Transformationen an, um die Effekte zu simulieren, die bei der Verwendung einer Handkamera auftreten, wie z. B. Verwackeln.
- Anschließend wird ein Hintergrund von zufällig aus im Internet geladenen Bildern hinzugefügt (z. B. ein unordentlicher Schreibtisch).
- Zuletzt fügen wir zusätzliche Beleuchtungsvariationen zu unserem Bild hinzu, einschließlich Helligkeits- und räumliche Gamma-Variationen, um eine Lichtquelle wie ein Kamerablitz zu simulieren.
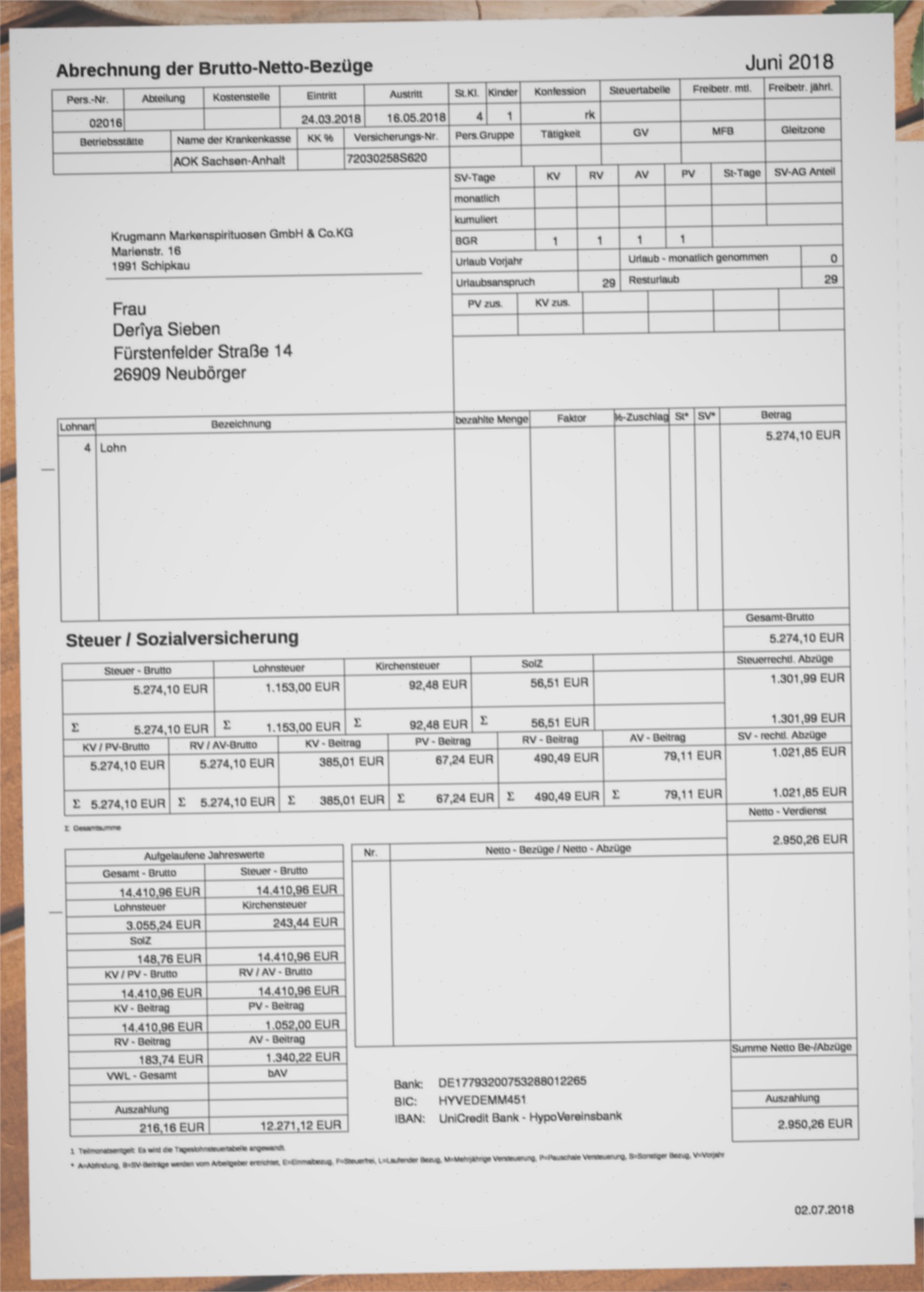
Unten siehst Du ein Beispiel für ein generiertes Dokument mit generierten Daten, sowie eine transformierte Variante davon.

Eine generierte Gehaltsabrechnung
Eine visuell manipulierte Variante der obigen Gehaltsabrechnung
Erste Ergebnisse
In einem vorläufigen Experiment erreichte das Trainieren eines Modells auf einem Datensatz mit ca. 20 % generierten Gehaltsabrechnungen eine um 2 % höhere Genauigkeit für eine extrahierte Information auf einem Testsatz von 199 Dokumenten im Vergleich zu einem Modell, das auf die gleiche Weise auf denselben Daten ohne generierte Dokumente trainiert wurde. Wir sind gespannt darauf, weitere Verbesserungen zu erzielen. In den kommenden Beiträgen werden wir genauer darauf eingehen, wie wir unsere Machine-Learning-Modelle entwickeln und wie wir sie in der Produktion einsetzen.
. . .
Wenn Du Spaß daran hast, Herausforderungen des Machine Learnings wie diese zu meistern, solltest Du Sie Dir unsere offenen Stellen ansehen. Wir sind immer auf der Suche nach exzellenten Entwicklern, die sich uns anschließen möchten!
Wir bei Gini möchten mit unseren Beiträgen, Artikeln, Leitfäden, Whitepaper und Pressemitteilungen alle Menschen erreichen. Deshalb betonen wir, dass sowohl weibliche, männliche als auch anderweitige Geschlechteridentitäten dabei ausdrücklich angesprochen werden. Sämtliche Personenbezeichnungen beziehen sich auf alle Geschlechter, auch dann, wenn in Inhalten das generische Maskulinum genutzt wird.



